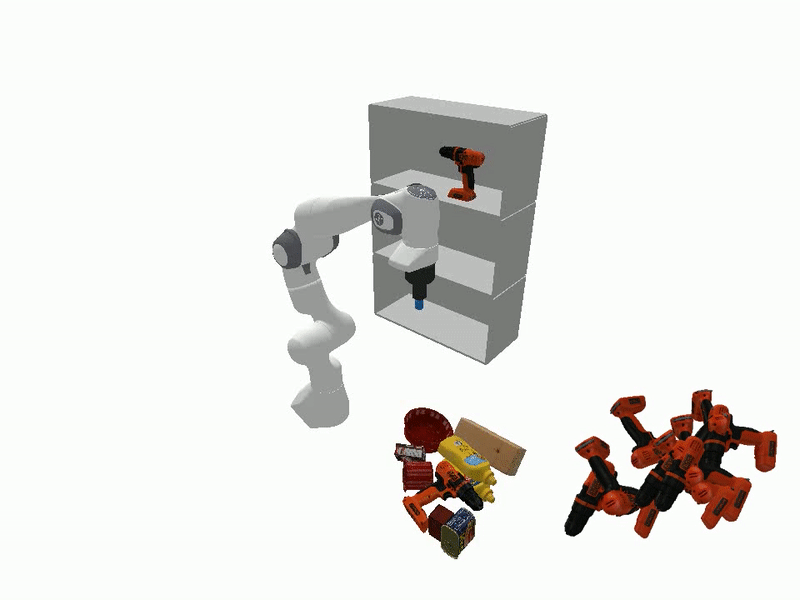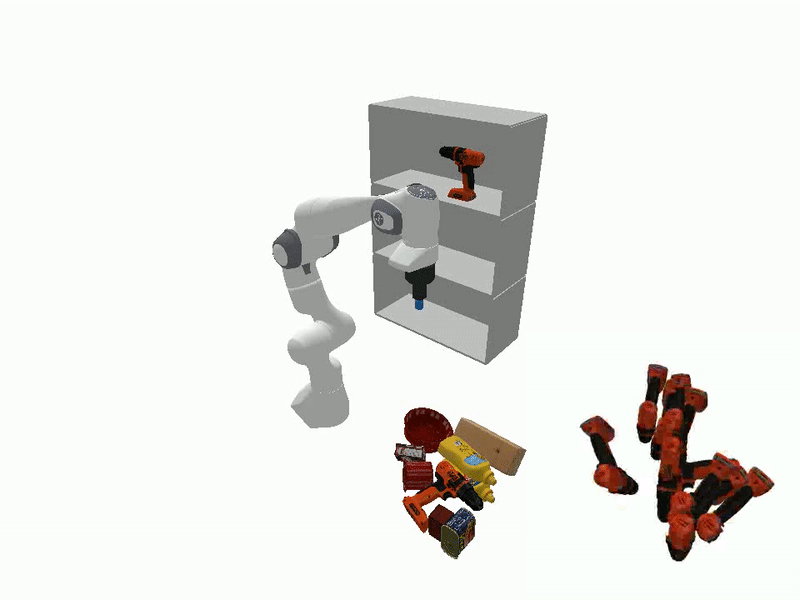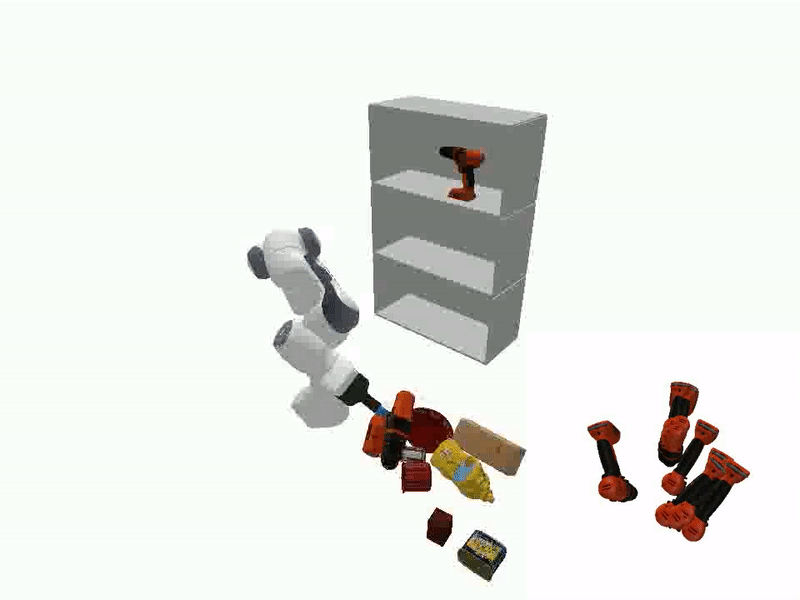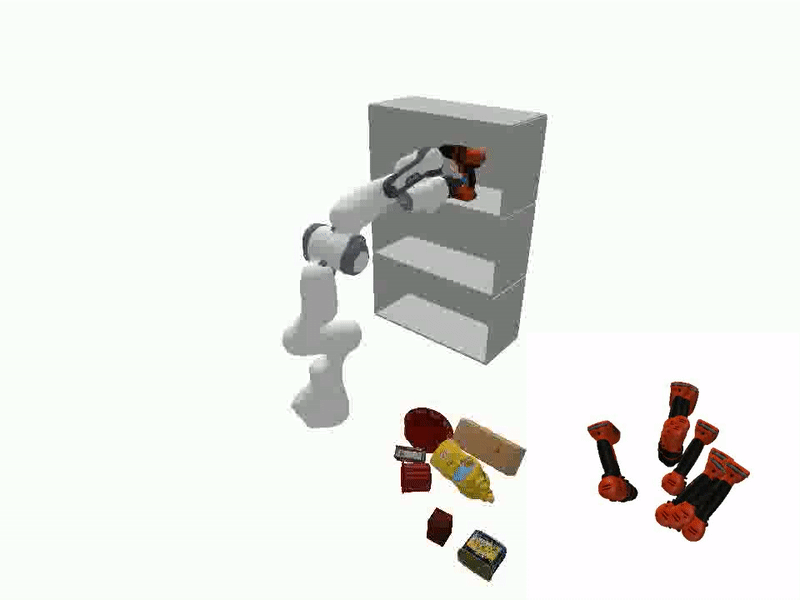ReorientDiff : Diffusion Model based Reorientation for Object Manipulation
In Submission
TL;DR: Diffusion Models for language-conditioned multi-step object manipulation for precise object placement.
Abstract
The ability to manipulate objects in a desired configurations is a fundamental requirement for robots to complete various practical applications. While certain goals can be achieved by picking and placing the objects of interest directly, object reorientation is needed for precise placement in most of the tasks. In such scenarios, the object must be reoriented and re-positioned into intermediate poses that facilitate accurate placement at the target pose. To this end, we propose a reorientation planning method, ReorientDiff, that utilizes a diffusion model-based approach. The proposed method employs both visual inputs from the scene, and goal-specific language prompts to plan intermediate reorientation poses. Specifically, the scene and language-task information are mapped into a joint scene-task representation feature space, which is subsequently leveraged to condition the diffusion model. The diffusion model samples intermediate poses based on the representation using classifier-free guidance and then uses gradients of learned feasibility-score models for implicit iterative pose-refinement. The proposed method is evaluated using a set of YCB-objects and a suction gripper, demonstrating a success rate of 95.2% in simulation. Overall, our study presents a promising approach to address the reorientation challenge in manipulation by learning a conditional distribution, which is an effective way to move towards more generalizable object manipulation.
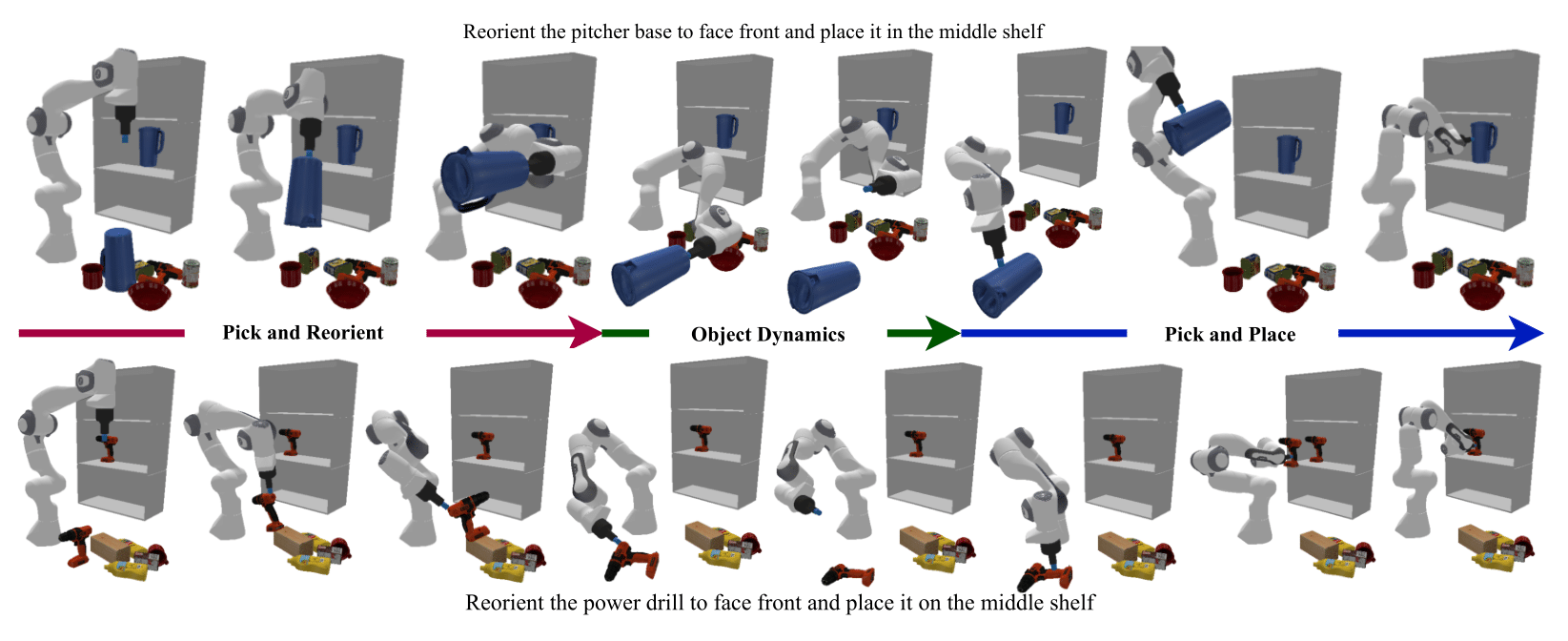
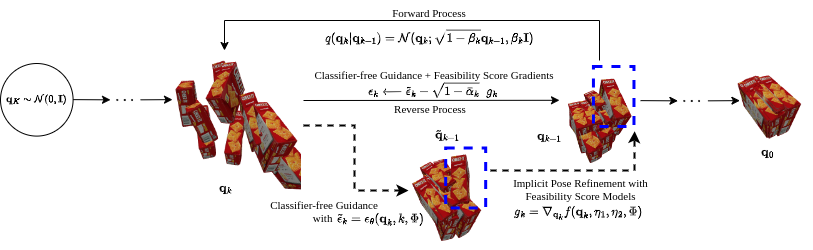
Method
(a). We construct the scene-task representation feature space by using pre-trained foundation model CLIP and a segmentation encoder:
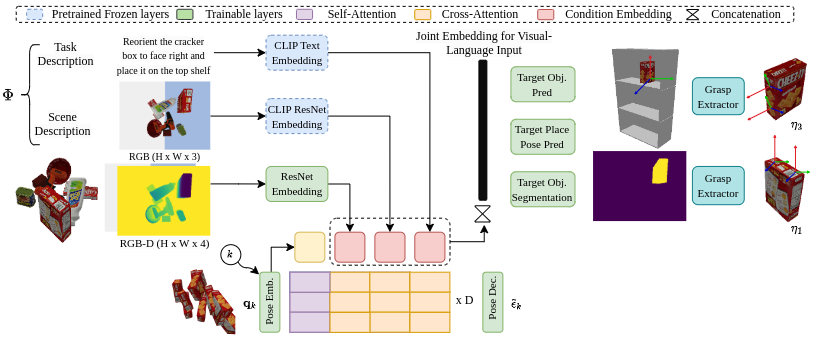
(b). We then use the scene-task representation to condition the diffusion model:
Experiments
Evaluating Scene Task representations
We evaluate our method on a set of YCB-objects and a suction gripper in simulation. The performance of the scene-task embedding network is shown in the following figure: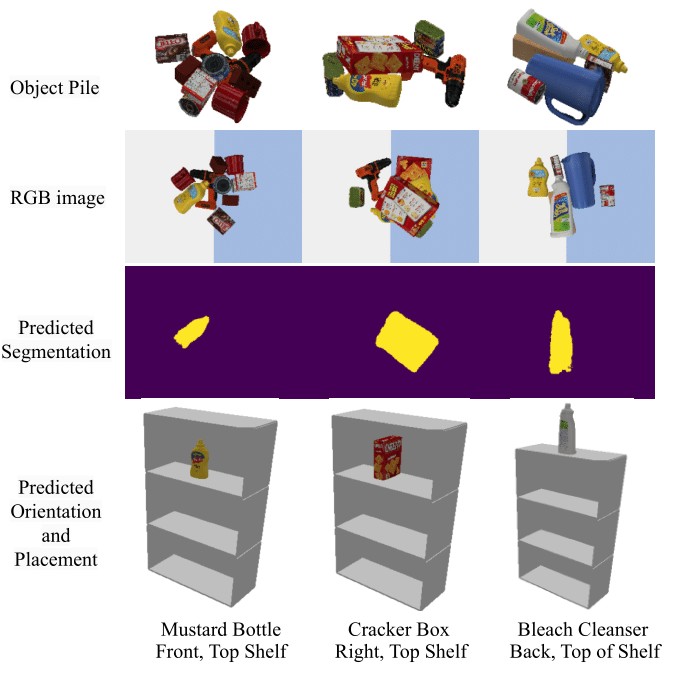
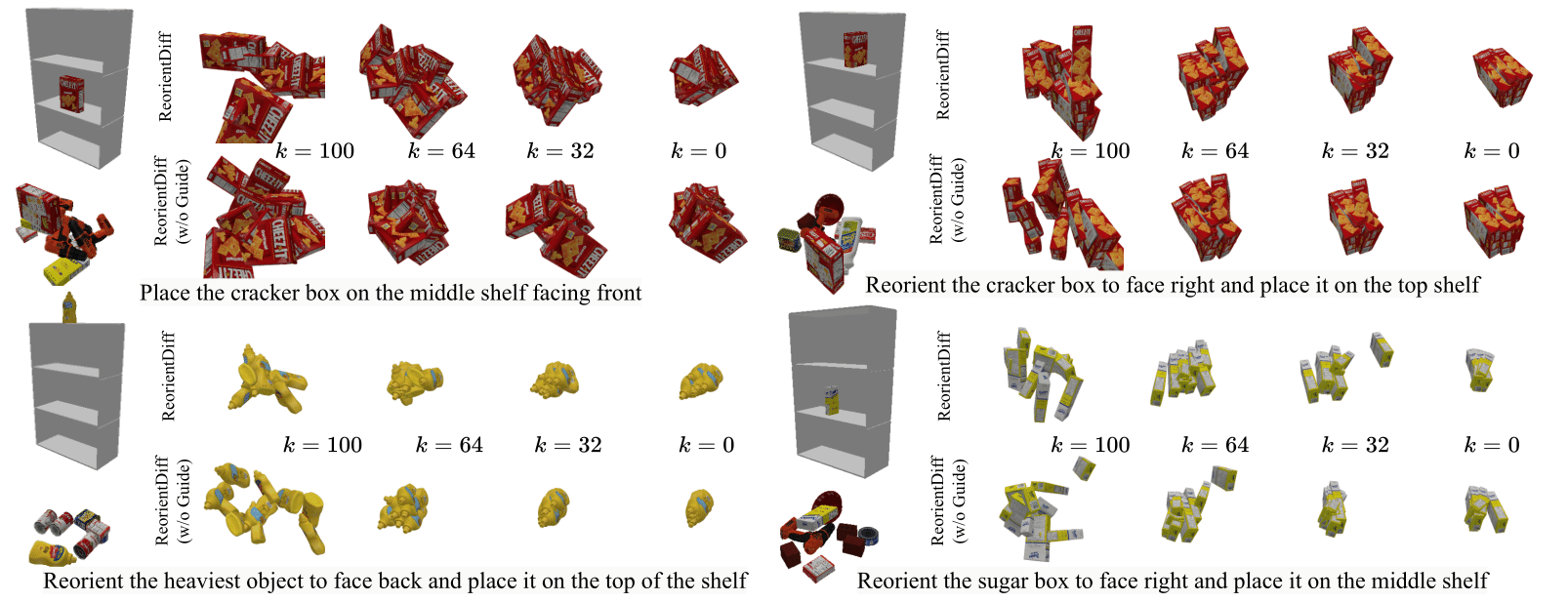
Diffusion Model Sampling performance
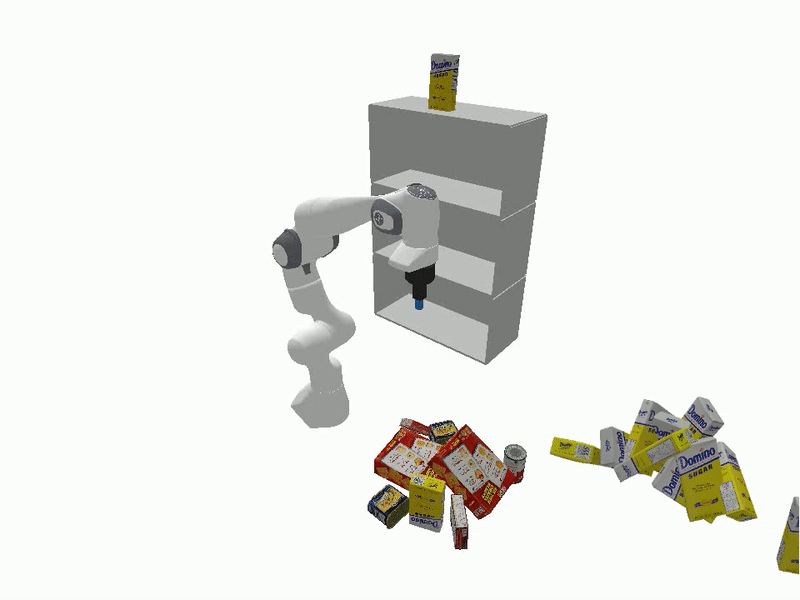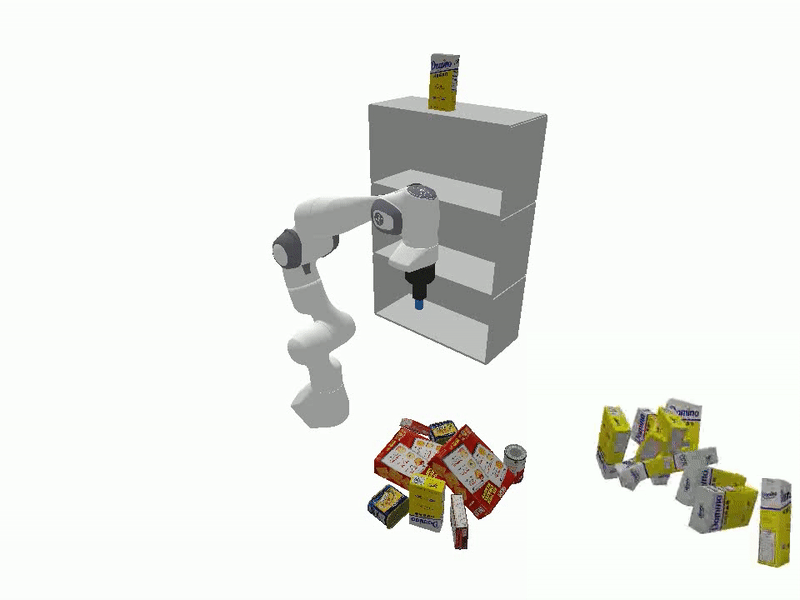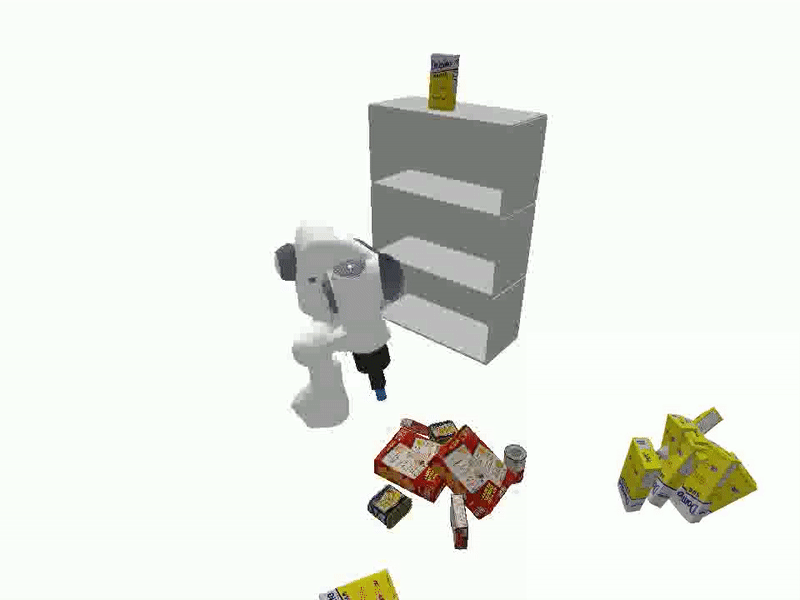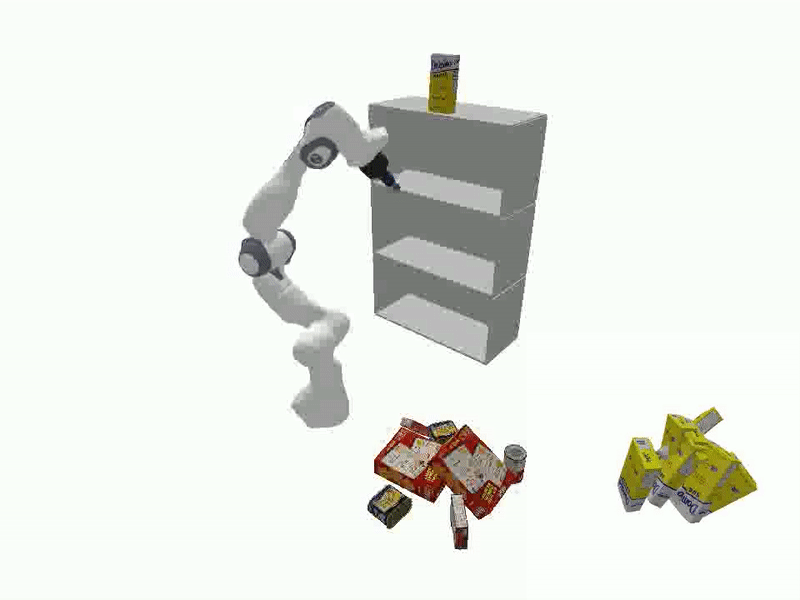
Videos of Robot Manipulation using Sampled Reorient Poses